Insights & Trends
Git + S3 for storing agent context
How Lark uses Git, S3, and isolated sandboxes to give AI agents durable context for writing, maintaining, and repairing long-lived E2E test suites.

Effective agents need durable context
Humans accumulate context over time. We remember what we tried, which approaches failed and we build up habits and conventions. When we return to a project after a week, we do not start from zero but agents do.
If an agent starts from a blank prompt every time, it is prone to making the same mistakes repeatedly. You can patch this by adding more instructions, but that gets brittle quickly.
Coding agents avoid some of this because the codebase itself is the context store. A repository gives the agent:
A filesystem - The agent can explore the project lazily instead of receiving everything in the prompt.
A durable memory layer - Git records what changed, when it changed, and often why it changed.
Executable state - The agent can run tests, scripts, linters, browsers, CLIs, and other tools.
If filesystem-based agents with Git history work well for coding, can we bring the same architecture to other agentic workflows?
Three ways to manage agent context
When people build agents, context usually ends up in one of three places:
1. Put everything in the prompt -
This is the simplest version. You gather the instructions, prior state, examples, docs, etc, and stuff them into the model context. This works for small workflows (like handling a simple customer support ticket), but often isn’t enough for more complicated long-lived workflows.
Over time the prompt becomes a dumping ground. Important details compete with stale details. The agent cannot easily discover context on demand.
2. Give the agent retrieval tools or a dedicated memory layer
This is better. The agent can search docs, query a vector database, inspect past conversations, pull relevant records from an external system, or use a separate memory layer that stores things it has learned from prior runs.
Retrieval via tools is useful, but still has some limitations. If the tools are not implemented properly, the agent still might have a problem of pulling in too much or too little context. Over time the overhead of managing context with tools also increases.
If you integrate a separate memory layer for agents, there’s overhead of managing that.
3. Represent context as files
This is how coding agents work. The agent gets a filesystem. The important state is represented as files. The agent can inspect only what it needs. It can modify those files. It can run commands against them. Git tracks the history.
For complex agents that output generated code or structured artifacts like JSON files, this is usually the best abstraction. We use this approach at Lark for our agents that generate E2E tests.
Architecting agents with sandboxes + S3 + Git
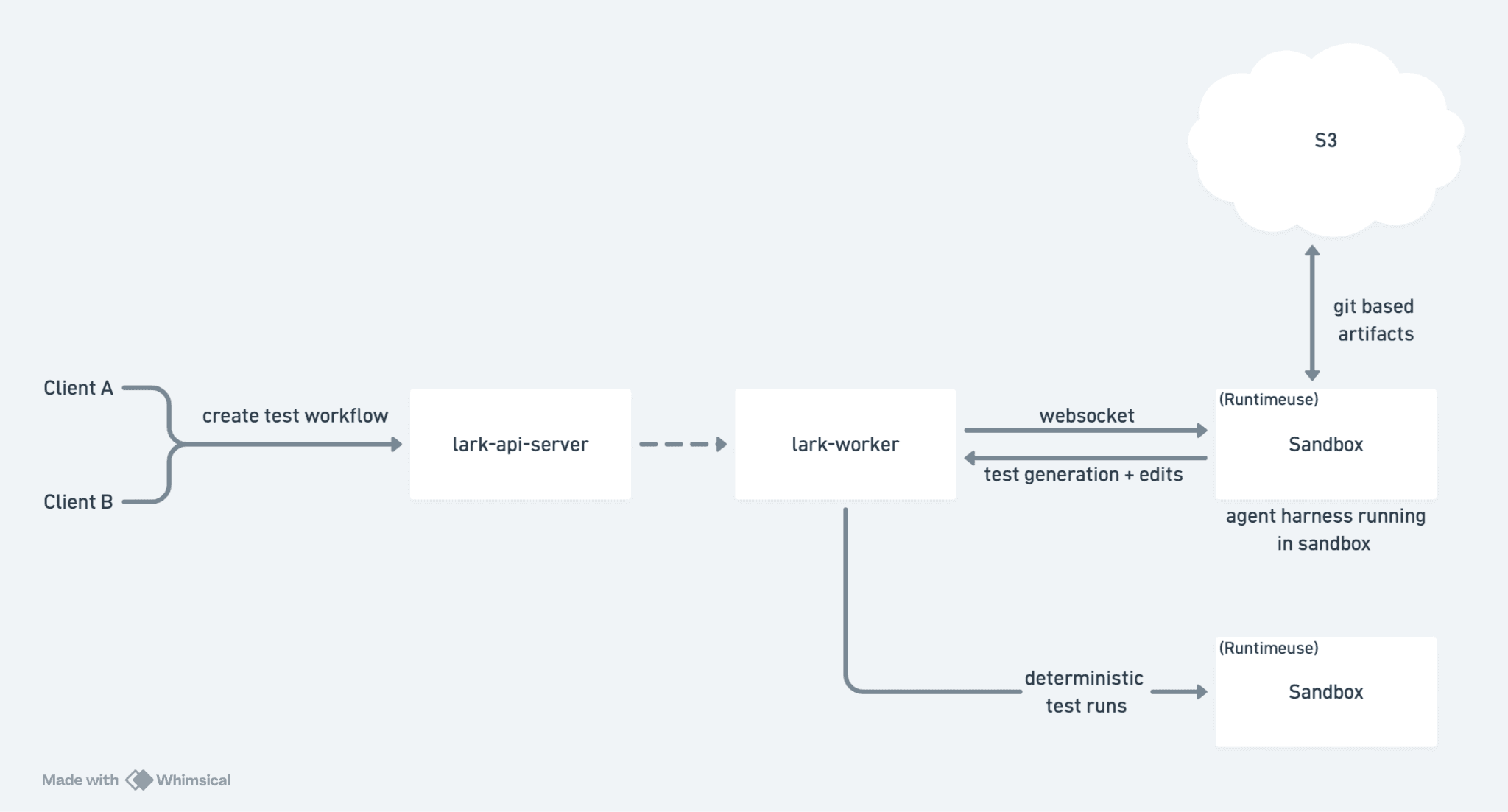
At Lark, one of the core jobs our agents perform is writing and maintaining E2E tests.
A user creates a test by describing a product flow in natural language. For example:
“Log in as an admin, create a customer, add a payment method, and verify that the customer appears in the billing dashboard.”
From there, the system turns that description into a long-lived test repository.
The high-level architecture looks like this:
Create a repository per test or test suite: We create an empty Git repository with some scaffolding every time a new testing workflow is created in Lark. This repository is meant for storing generated test code, metadata, run artifacts, repair notes, and whatever supporting files the agent needs.
Store the repository in S3-backed Git: We use Git as the interface and S3 as the durable backing store. git-remote-s3 is one way to do this.
Clone the repo into a sandbox: Each agent run happens in an isolated sandbox. The sandbox gives the agent a filesystem, shell, browser tooling, dependencies, and a safe place to execute code.
Run an agent harness inside the sandbox: The harness can use tools like Playwright to inspect and interact with the application. The agent can browse the app, write tests, run them, inspect failures, and iterate.
Commit the result back to Git: After the agent writes or modifies the test, we commit the change and push it back to the S3-backed remote. We use post-execution commands in RuntimeUse to handle this reliably after sandbox execution.
Run tests deterministically in future sandboxes: Test execution is separate from test generation. Once the code exists, it runs in a sandbox the same way CI would run it.
Why S3?
S3 is super simple to use and technical teams are already familiar with it. We wanted repositories to be cheap, durable, programmatically managed, and easy to create at high volume. S3 met the criteria.
The self-healing loop
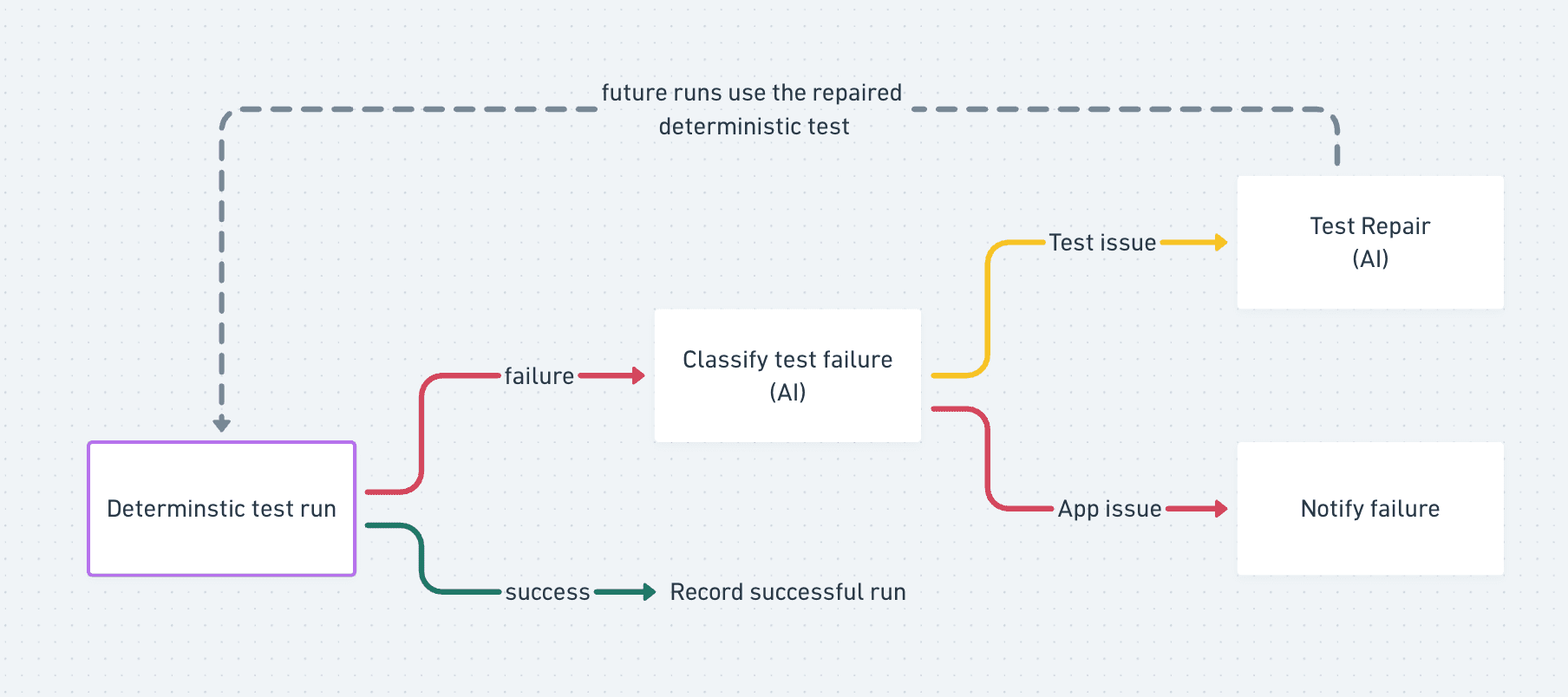
E2E tests can fail for different reasons – maybe the app is broken, maybe the product changed intentionally, or maybe the test was poorly written and is flaky.
When a Lark test fails, we analyze the run artifacts: logs, screenshots, videos, traces, network output, error messages, and prior test history. Then we decide whether the failure represents a real product issue or a test maintenance issue.
If it looks like a real product issue, we alert the user.
If it looks like a test issue, we start a repair loop:
Clone the existing test repository into a fresh sandbox.
Include context from the failed run as files in the sandbox directory.
Let the agent inspect the current test code and failure artifacts.
Let the agent run the test, update it, and verify the fix.
Commit the repaired test back to Git.
Use the repaired version on the next run.
The important detail is that the agent is not repairing from scratch. It is repairing an existing codebase with history. That is the same advantage coding agents have in normal software repositories.
Results
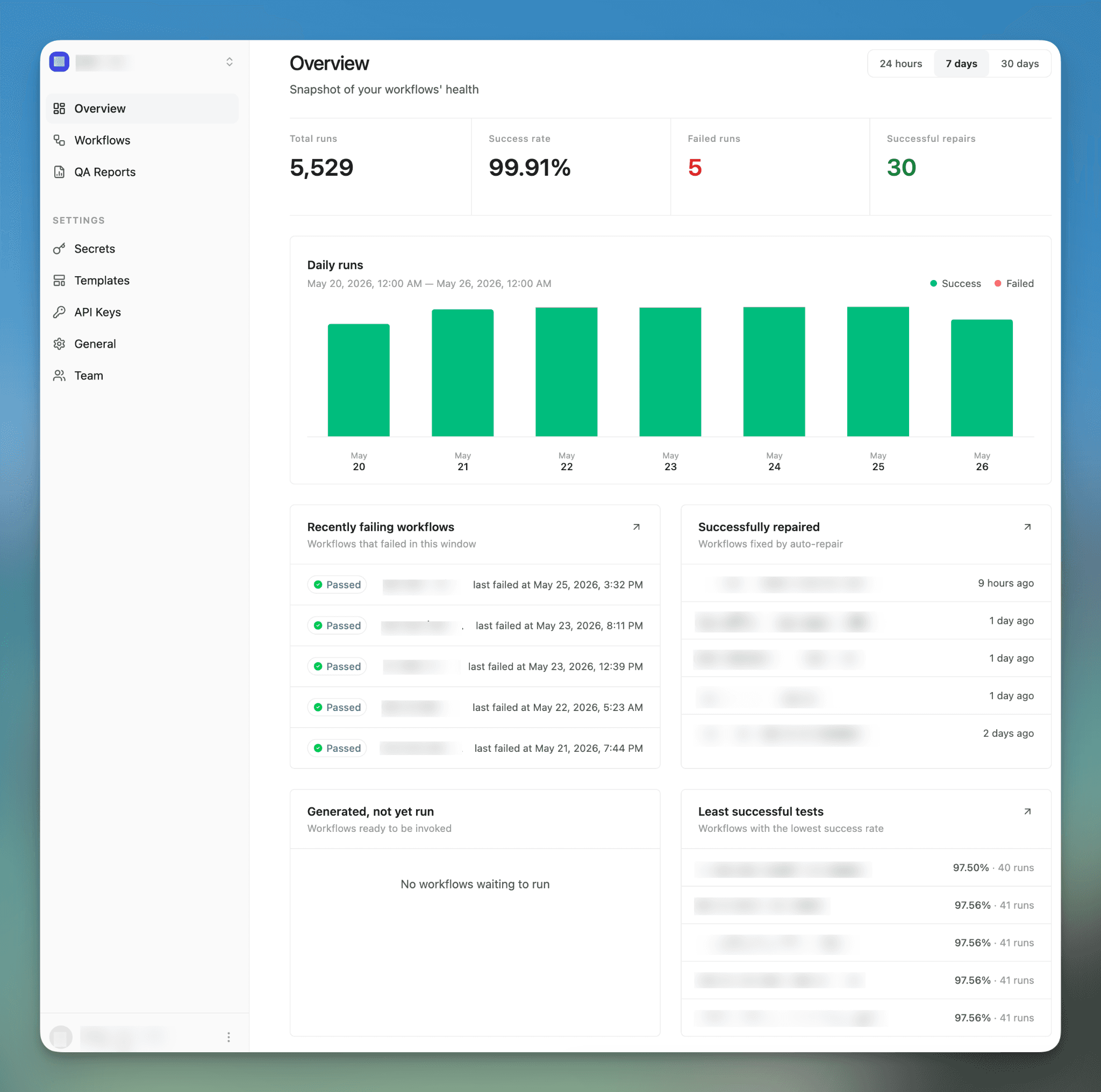
At Lark, this architecture lets us offer customers something close to a self-driving E2E test codebase.
A user can describe the flows they care about, and Lark’s agents generate the tests, run them continuously, repair them when the product changes, and alert when something appears genuinely broken.
Teams can create hundreds of E2E tests in minutes. Just last week, we onboarded a customer who is already running 5,000+ test executions per week across 100+ E2E tests.
That is the part that makes this architecture feel durable. The agent is not just producing one-off text. It is maintaining a living test codebase with history, execution, and feedback.
If you are building agents that produce or maintain long-lived artifacts, consider making the filesystem the context window and Git the memory layer. If you’d like to chat about this, feel free to reach out at team@getlark.ai.